
Migliorare le capacità dei sensori di visione: un algoritmo di aggregazione di immagini 3D per un ampliato campo visivo da Analog Devices
La crescente popolarità delle telecamere time of flight (TOF) nelle applicazioni industriali, in particolare nella robotica, è attribuita alle loro eccezionali capacità di calcolo della profondità e di elaborazione delle immagini a infrarossi (IR). Nonostante questi vantaggi, la complessità intrinseca del sistema ottico spesso limita il campo visivo, limitando le funzionalità autonome. In questo articolo viene illustrato un algoritmo di aggregazione di immagini 3D progettato per un processore host di supporto, che elimina la necessità di calcolo in cloud. Questo algoritmo combina in tempo reale e senza soluzione di continuità i dati IR e di profondità di più telecamere TOF, producendo un’immagine 3D continua e di alta qualità, con un campo visivo più ampio rispetto alle unità standalone. I dati 3D aggregati consentono l’applicazione di reti di deep learning allo stato dell’arte, particolarmente utili nelle applicazioni di robotica mobile, per rivoluzionare la visualizzazione e l’interazione con l’ambiente 3D.
Introduzione
Le telecamere time of flight (TOF) si distinguono come eccezionali sistemi di elaborazione di immagini del campo visivo, utilizzando le tecniche TOF per determinare la distanza tra una telecamera e ciascun punto di un’immagine. Ciò si ottiene misurando il tempo di andata e ritorno di un segnale di luce artificiale emesso da un laser o da un LED. Le telecamere TOF offrono informazioni precise sulla profondità, rendendole strumenti preziosi per le applicazioni in cui la misurazione accurata della distanza e la visualizzazione 3D sono fondamentali, come le applicazioni di robotica e tecnologia industriale, tra cui il rilevamento di collisione e il rilevamento di persone su un campo visivo (Field of View, FOV) di 270° per la sicurezza.
Il sensore TOF ADTF3175 può raggiungere un FOV calibrato di 75°. Tuttavia, le sfide sorgono quando il FOV di un’applicazione va oltre questa regione, richiedendo più sensori. L’integrazione dei dati provenienti dai singoli sensori per fornire un’analisi completa dell’intera vista può presentare delle difficoltà. Una soluzione potenziale prevede che i sensori eseguano un algoritmo su un FOV parziale e trasmettano l’output a un host per il confronto. Tuttavia, questo approccio deve affrontare problemi quali le zone di sovrapposizione, le zone morte e le latenze di comunicazione, che lo rendono un problema complesso da affrontare in modo efficace.
Un approccio alternativo prevede l’aggregazione dei dati acquisiti da tutti i sensori in un’unica immagine e la successiva applicazione di algoritmi di rilevamento all’immagine unita. Questo processo può essere scaricato su un processore host separato, sollevando le unità sensore dal carico computazionale e lasciando spazio ad analisi avanzate e altre opzioni di elaborazione. Tuttavia, è importante notare che gli algoritmi tradizionali di aggregazione delle immagini sono intrinsecamente complessi e possono consumare una parte significativa della potenza di calcolo del processore host. Inoltre, l’invio e l’aggregazione nel cloud non è possibile in molte applicazioni per motivi di privacy.
La soluzione algoritmica di Analog Devices è in grado di aggregare le immagini di profondità e IR provenienti dai diversi sensori, utilizzando le proiezioni delle nuvole di punti dei dati di profondità. Ciò comporta la trasformazione dei dati acquisiti utilizzando le posizioni estrinseche della telecamera e proiettandoli nuovamente nello spazio 2D, ottenendo un’unica immagine continua.
Questo approccio comporta una computazione minima, che aiuta a raggiungere velocità operative in tempo reale all’edge di rete e garantisce che la capacità di calcolo del processore host rimanga disponibile per altre analisi avanzate.
Descrizione di una Soluzione
La soluzione TOF 3D di ADI opera in quattro fasi (vedi Figura◦1):
- Preelaborazione dei dati IR e di profondità:
- Proiezione dei dati di profondità in una nuvola di punti 3D: Utilizzare i parametri intrinseci della telecamera per proiettare i dati di profondità in una nuvola di punti 3D.
- Trasformare e unire i punti: Trasformare i punti utilizzando le posizioni estrinseche della telecamera e unire le regioni sovrapposte.
- Proiezione della nuvola di punti in un’immagine 2D: Utilizzare la proiezione cilindrica per proiettare la nuvola di punti in un’immagine 2D.
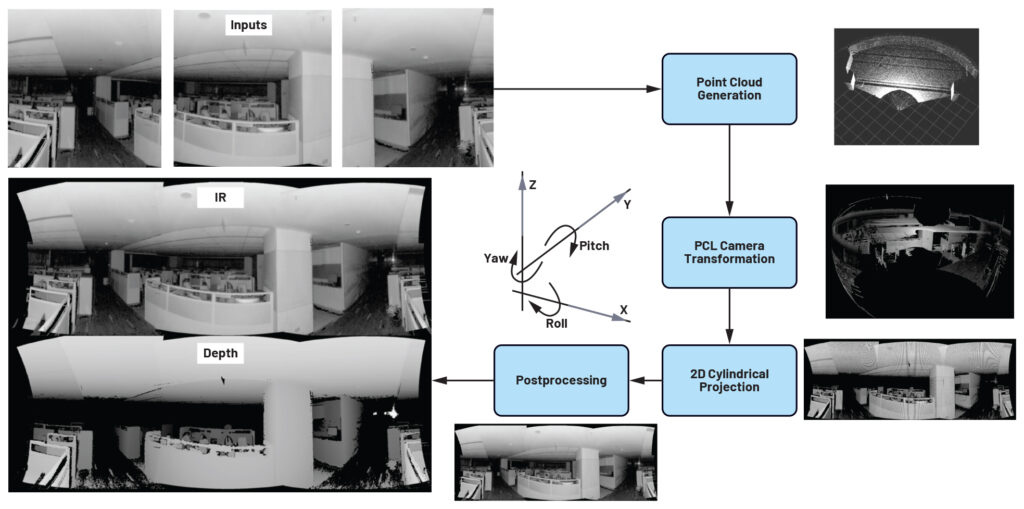
Sfide e soluzioni di sistema e algoritmo
L’ host riceve fotogrammi di profondità e IR
Una macchina host è collegata a più sensori TOF tramite una connessione ad alta velocità come l’USB. Raccoglie i fotogrammi di profondità e IR e li memorizza in una coda.
Sincronizzare i dati di profondità e IR
I fotogrammi di profondità e IR di ciascun sensore ricevuti dall’host vengono acquisiti in momenti diversi. Per evitare disallineamenti temporali dovuti al movimento degli oggetti, gli ingressi di tutti i sensori devono essere sincronizzati alla stessa istanza temporale. Si utilizza un modulo di sincronizzazione temporale che abbina i fotogrammi in arrivo in base ai timestamp della coda.
Dal progetto alla nuvola di punti
La nuvola di punti viene generata sull’host utilizzando i dati di profondità sincronizzati per ciascun sensore. Ogni nuvola di punti viene quindi trasformata (tradotta e ruotata) in base alle rispettive posizioni della telecamera (vedi Figura 2) nel mondo reale. Quindi queste nuvole di punti trasformate vengono unite per formare un’unica nuvola di punti continua che copre il FOV combinato dei sensori (Figura 3).

Proiezione da 3D a 2D
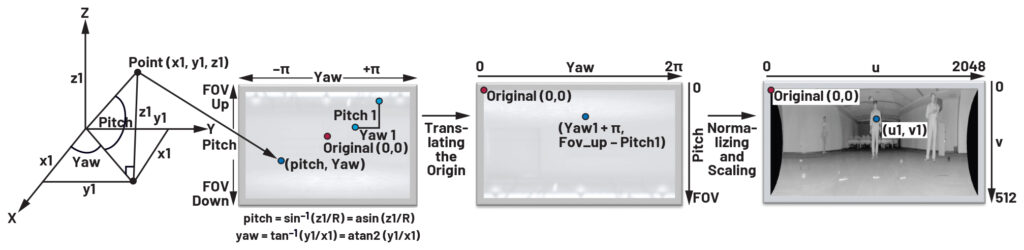
La nuvola di punti combinata del FOV viene proiettata su una superficie 2D utilizzando un algoritmo di proiezione cilindrica, noto anche come proiezione della vista frontale (vedi Figura 4). In altre parole, l’algoritmo proietta ogni punto della nuvola di punti combinata su un pixel del piano 2D, ottenendo un’unica immagine panoramica continua che copre il campo visivo combinato di tutti i sensori. Si ottengono così due immagini 2D aggregate: una per le immagini IR aggregate e un’altra per le immagini di profondità aggregate proiettate su piani 2D.
Miglioramento della qualità di proiezione
La proiezione della nuvola di punti combinata 3D su un’immagine 2D non fornisce ancora immagini di buona qualità, poiché presentano distorsioni e rumore. Ciò incide sulla qualità visiva e influisce negativamente su qualsiasi algoritmo venga eseguito sulla proiezione. I tre problemi principali (vedi Figura 5) e le relative soluzioni sono documentati nelle sezioni seguenti.
Proiezione di regioni di profondità non valide

I dati di profondità dell’ADTF3175 hanno un valore di profondità non valido di 0 mm per i punti che si trovano oltre il campo operativo del sensore (8000 mm). Ciò comporta la presenza di ampie regioni vuote nell’immagine di profondità e la formazione di nuvole di punti incomplete. A tutti i punti non validi dell’immagine di profondità è stato assegnato un valore di profondità di 8000 mm (la profondità massima supportata dalla telecamera), con il quale è stata generata una nuvola di punti. In questo modo è stato possibile garantire l’assenza di spazi vuoti nella nuvola di punti.
Riempimento dei pixel non mappati
Quando si proietta la nuvola di punti 3D su un piano 2D, nell’immagine 2D ci sono regioni non mappate/non riempite. Molti pixel della nuvola di punti (3D) vengono mappati sullo stesso pixel 2D e quindi diversi pixel 2D rimangono vuoti. Ciò comporta l’effetto di stiramento mostrato nella Figura 6. Per risolvere questo problema, è stato utilizzato un filtro 3 × 3 che riempie i pixel non mappati con il valore medio di IR/profondità degli 8 pixel vicini che hanno valori validi. In questo modo si è ottenuta una formazione più completa dell’immagine in uscita e gli artefatti sono stati rimossi (vedi Figura 6).
Rumore generato da punti sovrapposti
A causa dell’algoritmo di proiezione cilindrica, molti punti della regione di sovrapposizione finiscono per ottenere le stesse coordinate di appoggio sull’uscita 2D proiettata. Questo crea rumore quando i pixel di sfondo si sovrappongono a quelli in primo piano. Per risolvere questo problema, la distanza radiale di ogni punto viene confrontata con il punto esistente, e il punto viene sostituito solo se la distanza dall’origine della telecamera è inferiore al punto esistente. In questo modo si possono mantenere solo i punti in primo piano e migliorare la qualità della proiezione (vedi Figura 7).
Conclusione
Questo algoritmo è in grado di aggregare immagini provenienti da telecamere diverse con meno di 5° di sovrapposizione, rispetto ai 20° di sovrapposizione richiesti dai tradizionali algoritmi basati sulla corrispondenza dei punti chiave. Questo approccio richiede pochissimi calcoli, il che lo rende un candidato ideale per i sistemi all’edge di rete. L’integrità dei dati di profondità viene mantenuta anche dopo l’aggregazione, poiché non si verifica alcuna distorsione dell’immagine. Questa soluzione supporta ulteriormente l’implementazione modulare dei sensori ADTF3175 per ottenere il FOV desiderato con una perdita minima.
L’espansione del FOV non si limita alla dimensione orizzontale e la stessa tecnica può essere utilizzata per espandere la vista in verticale e ottenere una vera visione sferica. La soluzione funziona su una CPU Arm® V8 a 6 core a 10 fps per quattro sensori che forniscono un FOV di 275°. Il frame rate sale a 30 fps quando si utilizzano solo due sensori.
Uno dei vantaggi principali di questo approccio è l’enorme guadagno computazionale ottenuto: un guadagno di più di 3 volte nella computazione di base (vedi Tabella 1).
Le Figure 8 e 9 mostrano alcuni risultati ottenuti con questa soluzione.
Analog Devices ti aspetta a SPS Norimberga 2024 per trasformare il futuro del settore industriale presso il Padiglione 5, Stand 110. Maggiori informazioni sulla pagina ADI dedicata.
Tabella 1. Confronto tra complessità computazionali: algoritmi tradizionali su algoritmo proposto per input di 512 × 512 QMP
| Algoritmo | Operazioni in Virgola Mobile medie |
| Aggregazione immagini tradizionale | 857 milioni |
| Aggregazione di profondità PCL proposta | 260 milioni (Riduzione di 3,29 volte) |
Riferimenti
“Analog Devices 3DToF ADTF31xx.” GitHub, Inc.
“Analog Devices 3DToF Floor Detector.” GitHub, Inc.
“Analog Devices 3DToF Image Stitching.” GitHub, Inc.
“Analog Devices 3DToF Safety Bubble Detector.” GitHub, Inc.
“Analog Devices 3D ToF Software Suite.” GitHub, Inc.
He, Yingshen, Ge Li, Yiting Shao, Jing Wang, Yueru Chen, and Shan Liu. “A Point Cloud Compression Framework via Spherical Projection.” 2020 IEEE International Conference on Visual Communications and Image Processing, 2020.
Industrial Vision Technology. Analog Devices, Inc.
Topiwala, Anirudh. “Spherical Projection for Point Clouds.” Towards Data Science, Marzo 2020.
AUTORI:
Rajesh Mahapatra, Senior Manager, Analog Devices
Anil Sripadarao, Principal Engineer, Analog Devices
Swastik Mahapatra, Senior Engineer, Analog Devices
